High Availability
UDMG supports High Availability (HA) deployments by clustering multiple UDMG Server instances (referred as Cluster Nodes) into a coordinated configuration. This approach ensures that services remain available even if individual nodes fail, providing continuous operations for business-critical environments.
HA delivers several key benefits:
- Improved reliability: System uptime is maintained even during hardware or network failures.
- Zero downtime during failures: Traffic is automatically rerouted to healthy nodes.
- Scalability: Workloads can be distributed across multiple servers.
- Easier maintenance: Individual nodes can be updated or restarted without interrupting service.
For production environments where uninterrupted service is essential, deploying UDMG in an HA configuration is the recommended model.
Architecture Overview
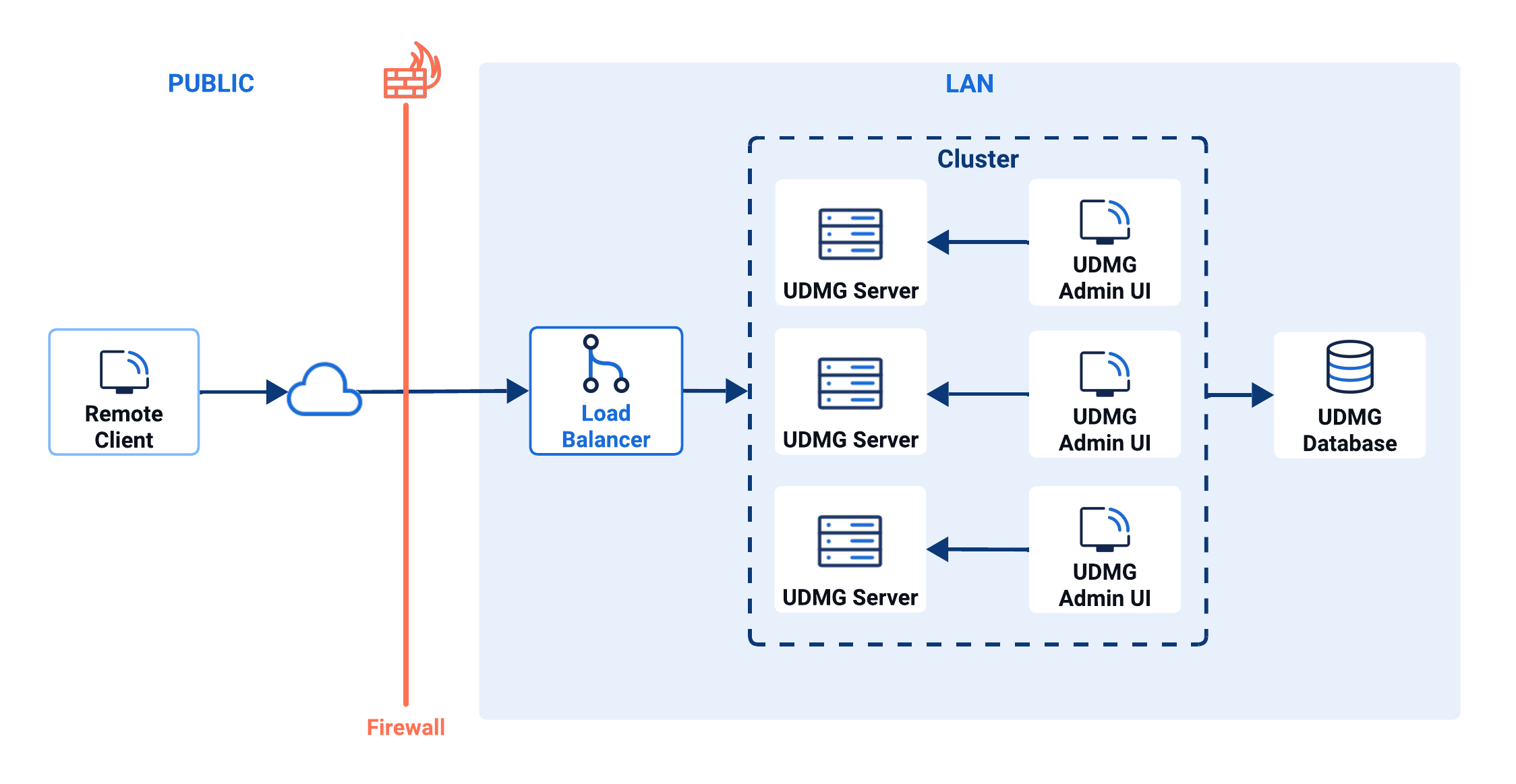
The recommended HA topology places a load balancer (not provided by UDMG) in front of multiple UDMG Server nodes that share a single database. The load balancer distributes requests and removes unhealthy nodes from rotation, while the shared database provides a single source of truth for configuration and runtime state.
For a complete description of how UDMG and USP integrate in HA deployments, see UDMG and USP in HA.
Components
| Component | Role |
|---|---|
| Remote Client | External clients (e.g., SFTP clients) that connect to UDMG. |
| Load Balancer | Receives client traffic, performs health checks, and routes requests to available UDMG Server nodes. It's not provided by UDMG. |
| Cluster | Coordination layer formed by the UDMG Server nodes to provide redundancy (Active/Passive) or shared workload (Active/Active). |
| Cluster Nodes (UDMG Servers) | Two or more UDMG Server instances that handle client requests in Active/Active or Active/Passive mode. |
| UDMG Admin UI (one per Cluster Node) | Two or more instances of the UDMG Admin UI for configuration and monitoring UDMG Server. |
| Shared UDMG Database | Central repository for configuration and operational data; the single source of truth used by all Cluster Nodes. |
How It Works
The UDMG high-availability cluster ensures consistency and continuity by coordinating all nodes through the shared database and load balancer:
- Configuration changes: When an administrator creates or updates a configuration item (such as a Domain, Endpoint, or Pipeline), the change is written to the shared database.
- Cluster synchronization: Each UDMG Server node automatically detects the update and synchronizes its local state. All nodes remain aligned with the same configuration and metadata.
- Request distribution: The load balancer (not provided by UDMG) receives incoming requests and forwards them to healthy nodes, distributing traffic evenly. Nodes that fail health checks are temporarily removed from rotation.
- Admin session handling: UDMG Admin User sessions are recognized across all UDMG Admin UI instances. A user can connect through any UI instance without losing session continuity.
- Transfer execution: File transfers run on a single node at a time, but management operations (such as cancellation) are cluster-wide. This ensures consistent control even if the transfer was initiated on another node.
Cluster Modes
UDMG clustering can operate in two different modes. Both improve resilience, but they offer different levels of availability and scalability.
| Mode | Description | Typical Use Case |
|---|---|---|
| Active/Passive (A/P) | A single node handles all traffic. One or more standby nodes remain idle and automatically take over if the active node becomes unavailable. | Simple redundancy where failover protection is sufficient. |
| Active/Active (A/A) | All nodes are active at the same time, sharing traffic and workload. If one node fails, other nodes continue operating seamlessly. | High availability and scalability in production environment. |
Configuring High Availability
To deploy UDMG in an HA environment, configure each UDMG Server (Cluster Node) through its Configuration File.
Although these parameters can also be set using Environment Variables, the configuration file approach is recommended because it keeps settings versioned, reviewable, and consistent across nodes.
All Cluster Nodes must share the same configuration to operate as part of the cluster.
Reuse the same HCL configuration file across all Cluster Nodes to ensure consistency.
You can either copy the file to each host or keep a single file in a shared location accessible by all nodes.
Limit differences to node-specific values (such as instance_name), which are best set through environment variables.
In each Cluster Node, configure the following:
- Shared database: Define the
databaseblock so that all nodes point to the same database, which acts as the Cluster's single source of truth.- All configuration changes, metadata, and operational state are written here.
- Cluster mode: Set
cluster.modeto control how nodes participate in the cluster."AA"(Active/Active): All nodes handle requests simultaneously, providing both high availability and load distribution."AP"(Active/Passive): A single active node handles traffic while standby nodes wait to take over in case of failure.
- Liveness timing: These parameters control how quickly the cluster detects and reacts to node failures. Use the defaults unless your environment requires tuning.
cluster.heartbeat: Interval at which each node sends "I am alive" signals to the cluster (default"10s"). Shorter values detect failures faster but increase cluster traffic.cluster.deadline: Maximum time a node can miss heartbeats before it is considered down (default"30s"). Must be greater thanheartbeatto avoid false positives.
- Cluster networking: These ports enable nodes to discover and communicate with each other. Defaults usually suffice, unless another application already uses the same ports.
cluster.client_port: Port that nodes use when joining the cluster (default4222). This is the entry point for initial connections to exchange cluster membership information.cluster.cluster_port: Port used for ongoing inter-node communication (default6222). This carries heartbeat signals, membership updates, and coordination messages.
Configuration Example
The values below are provided as an example. Use values appropriate for your environment, but ensure they are the same across all Cluster Nodes.
# 1. Shared database
database {
engine = "mysql"
instance = "udmg"
hostname = "database.fqdn.net"
port = 3306
user = "db-user"
password = "db-password"
}
# 2-4. Cluster settings
cluster {
mode = "AA" # "AA" or "AP"
heartbeat = "10s" # Interval between heartbeats
deadline = "30s" # Timeout to consider a node down
client_port = 4222 # Peers dial this
cluster_port = 6222 # Inter-node cluster traffic
}
Configuration Example Using HAProxy
An external load balancer must be configured to support high availability for UDMG. It should distribute client traffic across all available UDMG Server nodes and perform active health checks to detect when a node becomes unavailable. This ensures traffic is routed only to healthy, responsive nodes, maintaining uninterrupted service.
Each UDMG Server Cluster Node must run on a separate machine or virtual host to ensure fault isolation, resource independence, and consistent network binding. All nodes must point to the same database (single source of truth) and share the same configuration file (with only node-specific values—such as instance_name—differing via environment variables).
Below is one common HAProxy configuration. This example demonstrates how to load balance SFTP traffic across three UDMG Server instances:
- Three UDMG Server nodes:
192.168.1.20,192.168.1.21,192.168.1.22. - An SFTP service exposed by UDMG on port
2222(per node).
global
log stdout format raw local0
maxconn 4096
defaults
log global
option dontlognull
timeout connect 5s
timeout client 50s
timeout server 50s
# Optional HAProxy stats UI
frontend stats
mode http
bind *:8404
stats enable
stats uri /
stats refresh 30s
stats show-legends
stats show-node
# SFTP (SSH over TCP) load balancer
frontend udmg_sftp_frontend
mode tcp
bind *:2222
default_backend udmg_sftp_backend
backend udmg_sftp_backend
mode tcp
balance leastconn
# Optional: session stickiness by source IP
stick-table type ip size 100k expire 4h
stick on src
# Health check: expect SSH-2.0 banner from UDMG SFTP
option tcp-check
tcp-check expect comment UDMG\ SFTP\ check string SSH-2.0
# UDMG Server pool (three nodes)
server udmg1 192.168.1.20:2222 check inter 10s fall 3 rise 2
server udmg2 192.168.1.21:2222 check inter 10s fall 3 rise 2
server udmg3 192.168.1.22:2222 check inter 10s fall 3 rise 2
UDMG also exposes observability endpoints on each node that can be used by load balancers or monitoring tools for health checks:
/_/ping: confirms the node process is up./_/healthcheck: confirms the node is up and its dependencies (such as the database) are healthy.
These endpoints run on the HTTP(S) UDMG observability port of each node and are not tied to the SFTP port. Use them when you want deeper health validation in addition or instead of the SFTP banner check.
Monitoring HA Deployments
Use the Cluster Nodes page to track health and membership. For details about node-level status cards, counters, and alerts, see Cluster Nodes.